
BENCHMARK REPORT
The Numbers Your PII Vendor Doesn't Want You to See.
We ran Limina against AWS Comprehend, Azure Cognitive Services, Google DLP, and Microsoft Presidio—on call transcripts, medical records, emails, and chat logs. F1, precision, and recall across five real-world datasets. No cherry-picking.
Benchmark Report 🔒

.png)
.png)
.png)
.png)
.png)

.png)











WHAT'S INSIDE
Head-to-Head Benchmark Data
F1, precision, and recall scores for Limina vs. AWS Comprehend, Azure CS, Google DLP, and Microsoft Presidio—restricted to matching entity sets for a fair comparison.

FIVE REAL-WORLD DATA TYPES
Call transcripts, medical records, emails, chat logs, and general text.
Performance varies significantly across data types. See exactly where each tool breaks down.

RECALL AS A PRIMARY METRIC
Missed PII is a compliance event.
The report focuses on recall—what each tool misses—not just overall accuracy scores that can mask false negatives.

REGEX AND OPEN-SOURCE LIMITATIONS
Why pattern-based detection fails in production.
Transcription noise, multilingual text, and entity variants that rules can't anticipate.
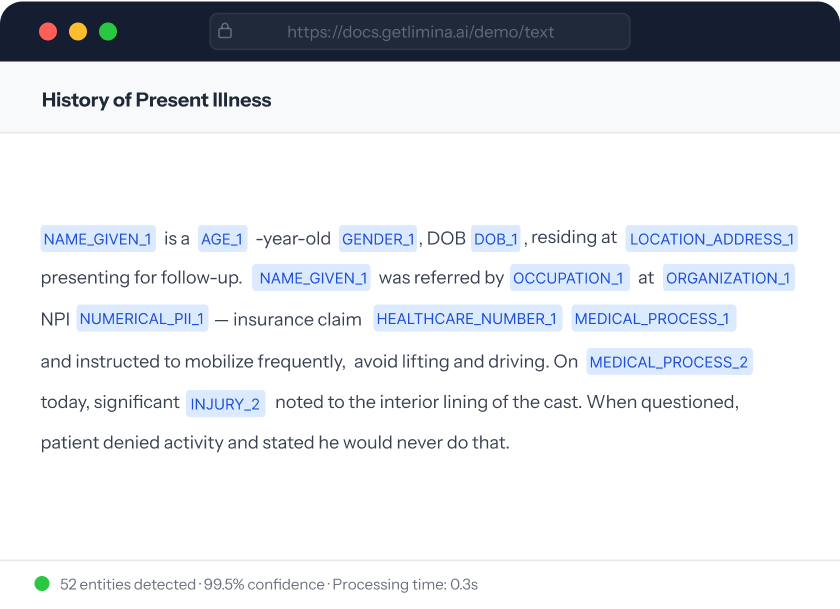
BY THE NUMBERS
99.5%
Out-of-the-box F1 score
4
Tools benchmarked head-to-head
5
Dataset types tested
0.3%
PII missed a % of total words