
BENCHMARK REPORT
AIのエコノミーのデータアクセスレイヤー
規制対象のデータを、使えるデータへ。Liminaは、52言語・あらゆるフォーマットからPII、PHI、PCIを検出・除去し、エキスパート判定に対応したワークフローを提供します。これにより、モデルの学習、インサイトの共有、AIプロダクトの構築を安全に実現することができます
Benchmark Report 🔒

.png)
.png)
.png)
.png)
.png)

.png)











WHAT'S INSIDE
Head-to-Head Benchmark Data
F1, precision, and recall scores for Limina vs. AWS Comprehend, Azure CS, Google DLP, and Microsoft Presidio—restricted to matching entity sets for a fair comparison.

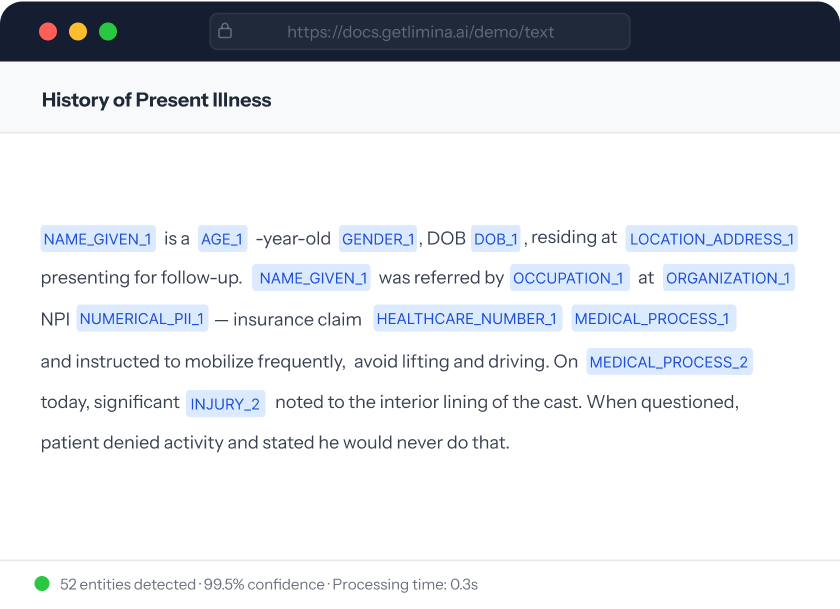
FIVE REAL-WORLD DATA TYPES
Call transcripts, medical records, emails, chat logs, and general text.
Performance varies significantly across data types. See exactly where each tool breaks down.

RECALL AS A PRIMARY METRIC
Missed PII is a compliance event.
The report focuses on recall—what each tool misses—not just overall accuracy scores that can mask false negatives.

REGEX AND OPEN-SOURCE LIMITATIONS
Why pattern-based detection fails in production.
Transcription noise, multilingual text, and entity variants that rules can't anticipate.
BY THE NUMBERS
99.5%
Out-of-the-box F1 score
4
Tools benchmarked head-to-head
5
Dataset types tested
0.3%
PII missed a % of total words